Building an Exercise Database: Multi-Source Data Normalization
Anyone who has tried to build a fitness application quickly discovers a frustrating reality: exercise data is scattered across dozens of sources, each with its own naming conventions, field structures, and quality standards. One API calls it “Dumbbell Bench Press,” another lists “Flat Bench Dumbbell Press,” and a third simply says “DB Bench.” They all mean the same exercise, but your database sees three distinct entries.
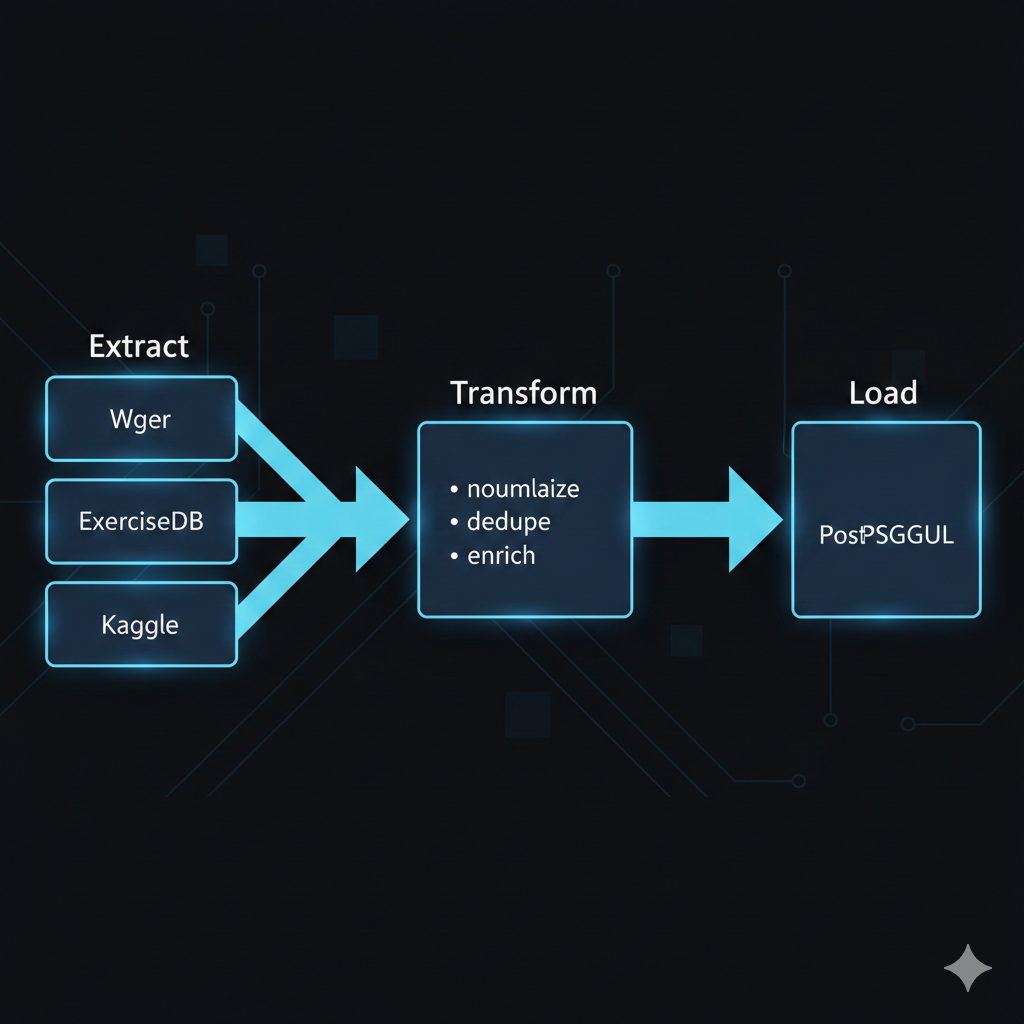
This article walks through building a normalized exercise database by aggregating data from the Wger API, ExerciseDB, and Kaggle datasets. The challenge extends beyond simple data merging - it requires entity resolution for exercises and equipment, fuzzy string matching for inconsistent naming, and a carefully designed PostgreSQL schema that maintains referential integrity while accommodating the inherent messiness of real-world fitness data.
By the end, you will have a working data pipeline architecture and practical code examples for tackling multi-source data normalization in any domain.
The data quality challenge
Before diving into solutions, understanding the specific problems helps frame the engineering decisions. Here is what raw data from three sources typically looks like:
| Source | Exercise Name | Equipment | Muscle Group |
|---|---|---|---|
| Wger API | ”Bench Press" | "Barbell" | "Chest” |
| ExerciseDB | ”barbell bench press" | "barbell" | "pectorals” |
| Kaggle | ”BENCH PRESS (BARBELL)" | "Barbell, Bench" | "Pectoralis Major” |
The same exercise appears with different casing, naming conventions, and muscle terminology. Equipment fields might be a single string, a comma-separated list, or completely missing. Some sources include detailed instructions while others provide only names.
Common data quality issues include:
- Inconsistent naming: “Lat Pulldown” vs “Cable Lat Pull-Down” vs “Pulldown - Lat”
- Missing fields: ExerciseDB lacks difficulty ratings; Wger often omits equipment
- Duplicate exercises: Same movement appears under multiple names or variations
- Conflicting metadata: Sources disagree on primary muscle groups
- Equipment ambiguity: “Machine” could mean dozens of different devices
A naive approach of simply concatenating datasets creates a bloated, inconsistent database. The solution requires normalization at multiple levels.
Fetching data from multiple APIs
The first step is building reliable data extraction from each source. Each API has quirks that the extraction layer must handle.
import requestsfrom typing import Iteratorfrom dataclasses import dataclassfrom time import sleep
@dataclassclass RawExercise: """Raw exercise data before normalization.""" source: str external_id: str name: str description: str | None equipment: list[str] muscles: list[str] category: str | None raw_data: dict # Original payload for debugging
class WgerExtractor: """Extract exercise data from Wger API."""
BASE_URL = "https://wger.de/api/v2"
def __init__(self, language: str = "en"): self.language = language self.session = requests.Session() self._equipment_cache: dict[int, str] = {} self._muscle_cache: dict[int, str] = {}
def _fetch_lookup_tables(self) -> None: """Pre-fetch equipment and muscle name mappings.""" # Equipment mapping (id -> name) resp = self.session.get(f"{self.BASE_URL}/equipment/") for item in resp.json()["results"]: self._equipment_cache[item["id"]] = item["name"]
# Muscle mapping (id -> name) resp = self.session.get(f"{self.BASE_URL}/muscle/") for item in resp.json()["results"]: self._muscle_cache[item["id"]] = item["name"]
def extract(self) -> Iterator[RawExercise]: """Yield all exercises from Wger API.""" self._fetch_lookup_tables()
url = f"{self.BASE_URL}/exercise/" params = {"language": 2, "limit": 100} # language=2 is English
while url: resp = self.session.get(url, params=params) resp.raise_for_status() data = resp.json()
for exercise in data["results"]: yield RawExercise( source="wger", external_id=str(exercise["id"]), name=exercise["name"], description=exercise.get("description"), equipment=[ self._equipment_cache.get(eid, f"unknown_{eid}") for eid in exercise.get("equipment", []) ], muscles=[ self._muscle_cache.get(mid, f"unknown_{mid}") for mid in exercise.get("muscles", []) ], category=exercise.get("category", {}).get("name"), raw_data=exercise, )
url = data.get("next") params = {} # Pagination URL includes params sleep(0.5) # Rate limitingExerciseDB requires a RapidAPI key and has a different structure:
class ExerciseDBExtractor: """Extract exercise data from ExerciseDB via RapidAPI."""
BASE_URL = "https://exercisedb.p.rapidapi.com"
def __init__(self, api_key: str): self.headers = { "X-RapidAPI-Key": api_key, "X-RapidAPI-Host": "exercisedb.p.rapidapi.com" }
def extract(self) -> Iterator[RawExercise]: """Yield all exercises from ExerciseDB.""" resp = requests.get( f"{self.BASE_URL}/exercises", headers=self.headers, params={"limit": 2000} ) resp.raise_for_status()
for exercise in resp.json(): yield RawExercise( source="exercisedb", external_id=exercise["id"], name=exercise["name"], description=exercise.get("instructions", [None])[0], equipment=[exercise["equipment"]] if exercise.get("equipment") else [], muscles=[exercise["target"]] if exercise.get("target") else [], category=exercise.get("bodyPart"), raw_data=exercise, )Note: Always store the
raw_datapayload. When normalization logic changes, having the original data avoids re-fetching from rate-limited APIs.
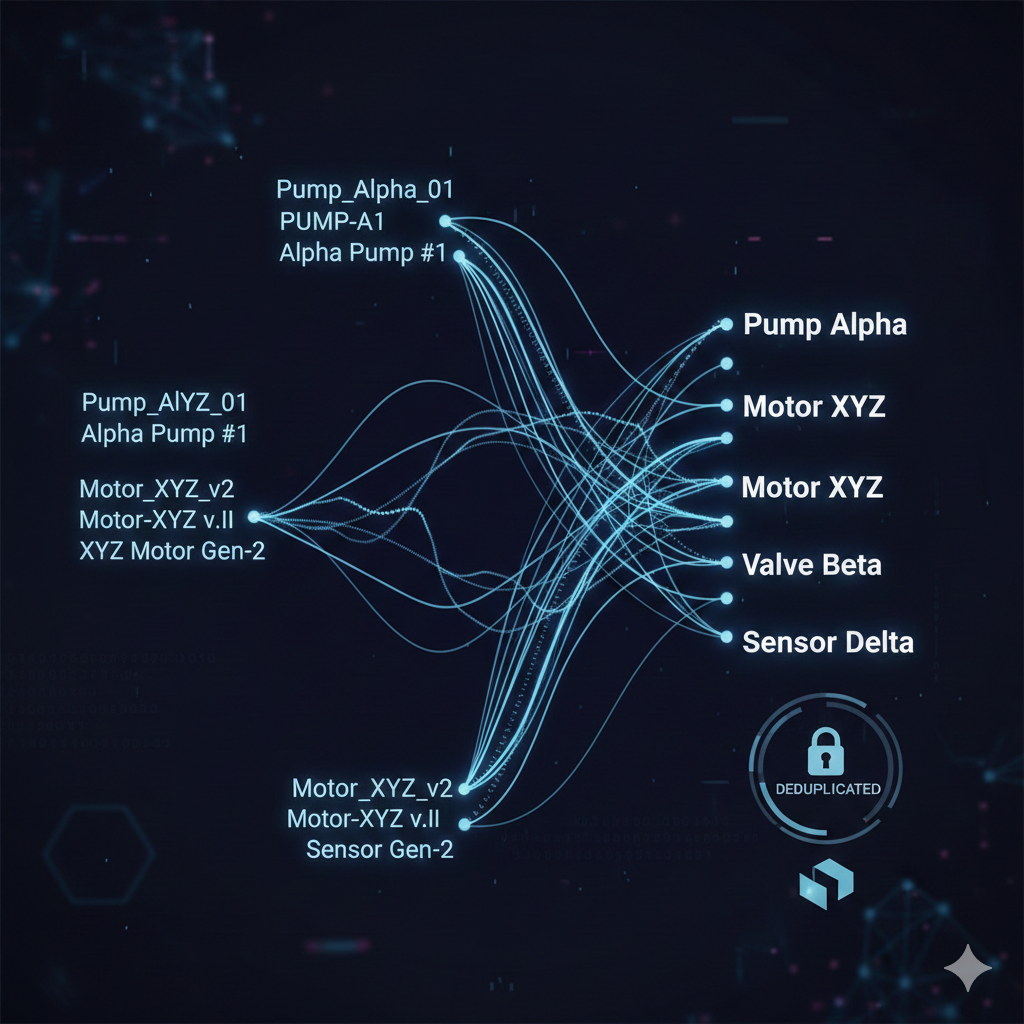
Fuzzy matching for equipment normalization
Equipment names vary wildly across sources. “Dumbbell,” “dumbbells,” “Dumbells” (misspelled), and “Free Weights - Dumbbell” should all resolve to the same canonical equipment entry.
The solution uses fuzzy string matching with the rapidfuzz library, combined with a manually curated list of canonical equipment names:
from rapidfuzz import fuzz, processfrom dataclasses import dataclass
@dataclassclass CanonicalEquipment: """Canonical equipment with known aliases.""" id: int name: str category: str aliases: list[str]
# Curated list of canonical equipmentCANONICAL_EQUIPMENT = [ CanonicalEquipment(1, "Barbell", "free_weights", ["barbell", "olympic bar", "standard bar", "bar"]), CanonicalEquipment(2, "Dumbbell", "free_weights", ["dumbbell", "dumbbells", "dumbells", "db", "free weights - dumbbell"]), CanonicalEquipment(3, "Cable Machine", "machines", ["cable", "cable machine", "pulley", "cable pulley", "cable stack"]), CanonicalEquipment(4, "Bodyweight", "bodyweight", ["bodyweight", "body weight", "none", "no equipment", "body only"]), CanonicalEquipment(5, "Kettlebell", "free_weights", ["kettlebell", "kettle bell", "kb"]), CanonicalEquipment(6, "Resistance Band", "accessories", ["band", "bands", "resistance band", "elastic band", "loop band"]), # ... 30+ more entries]
class EquipmentNormalizer: """Normalize equipment names to canonical forms."""
def __init__(self, threshold: int = 80): self.threshold = threshold self._build_lookup()
def _build_lookup(self) -> None: """Build alias -> canonical mapping.""" self.alias_map: dict[str, CanonicalEquipment] = {} self.all_aliases: list[str] = []
for equip in CANONICAL_EQUIPMENT: for alias in equip.aliases: normalized = alias.lower().strip() self.alias_map[normalized] = equip self.all_aliases.append(normalized)
def normalize(self, raw_name: str) -> CanonicalEquipment | None: """Resolve raw equipment name to canonical form.""" if not raw_name: return None
cleaned = raw_name.lower().strip()
# Exact match if cleaned in self.alias_map: return self.alias_map[cleaned]
# Fuzzy match match = process.extractOne( cleaned, self.all_aliases, scorer=fuzz.token_sort_ratio )
if match and match[1] >= self.threshold: return self.alias_map[match[0]]
return None # Unknown equipmentThe token_sort_ratio scorer handles word reordering (“Bench Press” matches “Press Bench”), which is common in exercise naming. A threshold of 80% catches typos while avoiding false positives.
Pro Tip: Log unmatched equipment names to a file. Reviewing these periodically reveals new aliases to add to the canonical list, improving match rates over time.
Entity resolution for exercises
Equipment normalization is relatively straightforward because the vocabulary is limited. Exercise resolution is harder - there are thousands of exercises with subtle variations.
The approach combines multiple signals:
- Fuzzy name matching for catching spelling variations
- Equipment overlap - exercises with the same name but different equipment are distinct
- Muscle group similarity - additional confidence signal
from rapidfuzz import fuzzfrom typing import NamedTupleimport hashlib
class ExerciseSignature(NamedTuple): """Unique signature for exercise deduplication.""" name_normalized: str equipment_ids: frozenset[int] primary_muscle: str | None
class ExerciseResolver: """Resolve exercises across sources to canonical entries."""
def __init__(self, equipment_normalizer: EquipmentNormalizer): self.equipment_normalizer = equipment_normalizer self.canonical_exercises: dict[str, dict] = {} # signature_hash -> exercise self.merge_log: list[dict] = [] # Track merge decisions for review
def _compute_signature(self, exercise: RawExercise) -> ExerciseSignature: """Compute deduplication signature for exercise.""" # Normalize name: lowercase, remove parentheticals, strip whitespace name = exercise.name.lower() name = re.sub(r'\([^)]*\)', '', name) # Remove (barbell), (dumbbell), etc. name = re.sub(r'[^a-z0-9\s]', '', name) # Remove punctuation name = ' '.join(name.split()) # Normalize whitespace
# Resolve equipment to canonical IDs equip_ids = set() for raw_equip in exercise.equipment: canonical = self.equipment_normalizer.normalize(raw_equip) if canonical: equip_ids.add(canonical.id)
# Primary muscle (first listed) primary = exercise.muscles[0].lower() if exercise.muscles else None
return ExerciseSignature(name, frozenset(equip_ids), primary)
def resolve(self, exercise: RawExercise) -> str: """Resolve exercise to canonical ID, creating if new.""" sig = self._compute_signature(exercise) sig_hash = hashlib.md5(str(sig).encode()).hexdigest()[:12]
# Check for existing match if sig_hash in self.canonical_exercises: existing = self.canonical_exercises[sig_hash] self.merge_log.append({ "action": "merged", "new_source": exercise.source, "new_name": exercise.name, "canonical_name": existing["name"], "signature": sig, }) return sig_hash
# Check fuzzy match against existing (catches near-duplicates) for existing_hash, existing in self.canonical_exercises.items(): name_score = fuzz.token_sort_ratio(sig.name_normalized, existing["signature"].name_normalized) equip_overlap = len(sig.equipment_ids & existing["signature"].equipment_ids)
if name_score > 90 and equip_overlap > 0: self.merge_log.append({ "action": "fuzzy_merged", "new_source": exercise.source, "new_name": exercise.name, "canonical_name": existing["name"], "name_score": name_score, }) return existing_hash
# New canonical exercise self.canonical_exercises[sig_hash] = { "name": exercise.name, # Keep first-seen name as canonical "signature": sig, "sources": [exercise.source], } return sig_hashThe merge log is critical for debugging. When users report missing exercises or incorrect merges, the log shows exactly why decisions were made.
PostgreSQL schema design
The normalized schema separates concerns into distinct tables with proper foreign key relationships:
-- Canonical equipment entriesCREATE TABLE equipment ( id SERIAL PRIMARY KEY, name VARCHAR(100) NOT NULL UNIQUE, category VARCHAR(50) NOT NULL, created_at TIMESTAMP DEFAULT NOW());
-- Muscle groups with hierarchyCREATE TABLE muscle_groups ( id SERIAL PRIMARY KEY, name VARCHAR(100) NOT NULL UNIQUE, parent_id INTEGER REFERENCES muscle_groups(id), body_region VARCHAR(50) -- upper, lower, core);
-- Canonical exercises (deduplicated)CREATE TABLE exercises ( id VARCHAR(12) PRIMARY KEY, -- Hash-based ID for determinism name VARCHAR(200) NOT NULL, description TEXT, difficulty VARCHAR(20), created_at TIMESTAMP DEFAULT NOW(), updated_at TIMESTAMP DEFAULT NOW());
-- Many-to-many: exercises <-> equipmentCREATE TABLE exercise_equipment ( exercise_id VARCHAR(12) REFERENCES exercises(id) ON DELETE CASCADE, equipment_id INTEGER REFERENCES equipment(id) ON DELETE CASCADE, is_primary BOOLEAN DEFAULT FALSE, PRIMARY KEY (exercise_id, equipment_id));
-- Many-to-many: exercises <-> muscle groupsCREATE TABLE exercise_muscles ( exercise_id VARCHAR(12) REFERENCES exercises(id) ON DELETE CASCADE, muscle_group_id INTEGER REFERENCES muscle_groups(id) ON DELETE CASCADE, involvement VARCHAR(20) DEFAULT 'primary', -- primary, secondary, stabilizer PRIMARY KEY (exercise_id, muscle_group_id, involvement));
-- Source tracking for provenanceCREATE TABLE exercise_sources ( id SERIAL PRIMARY KEY, exercise_id VARCHAR(12) REFERENCES exercises(id) ON DELETE CASCADE, source_name VARCHAR(50) NOT NULL, external_id VARCHAR(100), original_name VARCHAR(200), raw_data JSONB, fetched_at TIMESTAMP DEFAULT NOW(), UNIQUE (source_name, external_id));
-- Indexes for common queriesCREATE INDEX idx_exercises_name_trgm ON exercises USING gin (name gin_trgm_ops);CREATE INDEX idx_exercise_sources_exercise ON exercise_sources(exercise_id);CREATE INDEX idx_exercise_equipment_equip ON exercise_equipment(equipment_id);CREATE INDEX idx_exercise_muscles_muscle ON exercise_muscles(muscle_group_id);Key design decisions:
- Hash-based exercise IDs ensure the same exercise gets the same ID across pipeline runs
- JSONB
raw_datacolumn preserves original payloads without schema rigidity - Trigram index (
gin_trgm_ops) enables fast fuzzy search in PostgreSQL - Involvement levels for muscles capture that some exercises work a muscle as stabilizer vs. primary mover
Pro Tip: Enable the
pg_trgmextension withCREATE EXTENSION pg_trgm;before creating the trigram index.
Data pipeline architecture
The complete pipeline follows an Extract-Transform-Load pattern with clear stage separation:
from dataclasses import dataclassfrom datetime import datetimeimport logging
@dataclassclass PipelineConfig: """Configuration for the ETL pipeline.""" wger_enabled: bool = True exercisedb_api_key: str | None = None kaggle_path: str | None = None fuzzy_threshold: int = 80 batch_size: int = 100
class ExercisePipeline: """Orchestrate the exercise data ETL pipeline."""
def __init__(self, config: PipelineConfig, db_connection): self.config = config self.db = db_connection self.equipment_normalizer = EquipmentNormalizer(config.fuzzy_threshold) self.exercise_resolver = ExerciseResolver(self.equipment_normalizer) self.logger = logging.getLogger(__name__)
def run(self) -> dict: """Execute full pipeline, return statistics.""" stats = {"extracted": 0, "merged": 0, "loaded": 0, "errors": 0} start_time = datetime.now()
# Extract from all configured sources raw_exercises = []
if self.config.wger_enabled: self.logger.info("Extracting from Wger API...") for ex in WgerExtractor().extract(): raw_exercises.append(ex) stats["extracted"] += 1
if self.config.exercisedb_api_key: self.logger.info("Extracting from ExerciseDB...") for ex in ExerciseDBExtractor(self.config.exercisedb_api_key).extract(): raw_exercises.append(ex) stats["extracted"] += 1
if self.config.kaggle_path: self.logger.info("Extracting from Kaggle dataset...") for ex in KaggleExtractor(self.config.kaggle_path).extract(): raw_exercises.append(ex) stats["extracted"] += 1
self.logger.info(f"Extracted {stats['extracted']} raw exercises")
# Transform: resolve to canonical exercises canonical_map: dict[str, list[RawExercise]] = {} for raw in raw_exercises: try: canonical_id = self.exercise_resolver.resolve(raw) if canonical_id not in canonical_map: canonical_map[canonical_id] = [] canonical_map[canonical_id].append(raw) except Exception as e: self.logger.error(f"Resolution failed for {raw.name}: {e}") stats["errors"] += 1
stats["merged"] = stats["extracted"] - len(canonical_map) self.logger.info(f"Resolved to {len(canonical_map)} canonical exercises")
# Load to PostgreSQL self._load_equipment() self._load_exercises(canonical_map) stats["loaded"] = len(canonical_map)
# Save merge log for review self._save_merge_log()
stats["duration_seconds"] = (datetime.now() - start_time).total_seconds() return stats
def _load_exercises(self, canonical_map: dict[str, list[RawExercise]]) -> None: """Load canonical exercises with all relationships.""" with self.db.cursor() as cur: for canonical_id, sources in canonical_map.items(): # Use first source's data as primary, enrich from others primary = sources[0]
# Merge descriptions (take longest) description = max( (s.description for s in sources if s.description), key=len, default=None )
# Insert canonical exercise cur.execute(""" INSERT INTO exercises (id, name, description) VALUES (%s, %s, %s) ON CONFLICT (id) DO UPDATE SET description = COALESCE(EXCLUDED.description, exercises.description), updated_at = NOW() """, (canonical_id, primary.name, description))
# Insert source tracking for source in sources: cur.execute(""" INSERT INTO exercise_sources (exercise_id, source_name, external_id, original_name, raw_data) VALUES (%s, %s, %s, %s, %s) ON CONFLICT (source_name, external_id) DO NOTHING """, (canonical_id, source.source, source.external_id, source.name, Json(source.raw_data)))
# Insert equipment relationships for raw_equip in primary.equipment: canonical_equip = self.equipment_normalizer.normalize(raw_equip) if canonical_equip: cur.execute(""" INSERT INTO exercise_equipment (exercise_id, equipment_id) VALUES (%s, %s) ON CONFLICT DO NOTHING """, (canonical_id, canonical_equip.id))
self.db.commit()The pipeline is idempotent - running it multiple times produces the same result thanks to ON CONFLICT clauses. This allows safe re-runs when adding new sources or updating normalization logic.
Handling edge cases with machine learning
For exercises that fuzzy matching cannot resolve, a lightweight ML classifier provides additional signal:
from sklearn.feature_extraction.text import TfidfVectorizerfrom sklearn.metrics.pairwise import cosine_similarityimport numpy as np
class ExerciseSimilarityModel: """ML-based exercise similarity for edge cases."""
def __init__(self): self.vectorizer = TfidfVectorizer( ngram_range=(1, 3), max_features=5000, stop_words='english' ) self.exercise_vectors = None self.exercise_ids = []
def fit(self, exercises: list[tuple[str, str]]) -> None: """Fit on (id, name+description) tuples.""" self.exercise_ids = [ex[0] for ex in exercises] texts = [ex[1] for ex in exercises] self.exercise_vectors = self.vectorizer.fit_transform(texts)
def find_similar(self, name: str, description: str = "", top_k: int = 5) -> list[tuple[str, float]]: """Find similar exercises by text similarity.""" query_text = f"{name} {description}" query_vec = self.vectorizer.transform([query_text])
similarities = cosine_similarity(query_vec, self.exercise_vectors).flatten() top_indices = np.argsort(similarities)[-top_k:][::-1]
return [ (self.exercise_ids[i], float(similarities[i])) for i in top_indices if similarities[i] > 0.3 # Minimum threshold ]This model runs as a secondary check when fuzzy matching confidence is low, providing human reviewers with likely matches to verify.
Key takeaways
Building a normalized exercise database from multiple sources requires layered approaches:
- Separate extraction from transformation - APIs change; keeping raw data allows re-processing without re-fetching
- Build canonical entity lists for equipment - the vocabulary is finite and worth curating manually
- Use fuzzy matching with logging - the
rapidfuzzlibrary withtoken_sort_ratiohandles most naming variations; logs enable continuous improvement - Design schemas for provenance - tracking which source contributed what data aids debugging and data quality monitoring
- Make pipelines idempotent -
ON CONFLICTclauses in PostgreSQL enable safe re-runs - Reserve ML for edge cases - simple heuristics solve 90% of matches; ML handles the ambiguous remainder
The patterns here generalize beyond fitness data. Any domain with multiple data sources - product catalogs, medical records, geographic entities - benefits from this normalization architecture.
The complete pipeline reduces thousands of duplicate exercise entries to a clean, searchable database with full provenance tracking. More importantly, it establishes a foundation that improves over time as new aliases and edge cases are discovered and incorporated.