Aggregating Data from Multiple APIs: Patterns and Pitfalls
Introduction
Modern applications rarely exist in isolation. A typical dashboard might pull user data from your authentication provider, metrics from your analytics platform, inventory from your ERP system, and notifications from a third-party messaging service. Each API has its own quirks: different authentication schemes, inconsistent response formats, varying rate limits, and unpredictable availability windows.
This is the multi-API aggregation challenge: how do you combine data from disparate sources into a unified, reliable response for your application? The naive approach of sequential HTTP calls quickly falls apart. One slow API blocks the entire response. One failed service crashes your page. Rate limits get exhausted because you’re making redundant requests.
In this article, we’ll explore battle-tested patterns for aggregating data from multiple APIs using Python’s async capabilities. We’ll cover concurrent fetching, rate limiting, response normalization, caching strategies, and resilience patterns like circuit breakers. By the end, you’ll have a toolkit for building aggregation services that are fast, reliable, and maintainable.
The challenges of multi-API aggregation
Before diving into solutions, let’s understand what makes API aggregation genuinely difficult:
Rate limiting across providers
Every API has rate limits, but they’re rarely consistent:
| Provider | Rate Limit | Window | Penalty |
|---|---|---|---|
| GitHub API | 5,000 req | per hour | 403 until reset |
| Stripe API | 100 req | per second | 429 with retry-after |
| OpenAI API | Varies by tier | per minute | 429 with exponential backoff |
| Twitter/X API | 15 req | per 15 min | 429, 15-min lockout |
Aggregating across these providers means tracking multiple rate limit budgets simultaneously and gracefully degrading when any one is exhausted.
Format inconsistency
APIs speak different dialects. One returns created_at as a Unix timestamp, another as ISO 8601, a third as a human-readable string. User IDs might be integers, UUIDs, or opaque strings. Pagination uses cursors in one API and page numbers in another.
Availability variance
External APIs fail. They fail in different ways (timeouts, 5xx errors, malformed responses), at different rates, and with different recovery patterns. Your aggregation layer must handle partial failures gracefully, returning what data is available rather than failing entirely.
Async fetching with httpx
Python’s asyncio combined with httpx provides the foundation for efficient concurrent API calls. Instead of waiting for each API sequentially, we can fire requests in parallel and gather results.
import asyncioimport httpxfrom typing import Anyfrom dataclasses import dataclass
@dataclassclass APIResponse: source: str data: dict[str, Any] | None error: str | None status_code: int | None
async def fetch_api( client: httpx.AsyncClient, name: str, url: str, headers: dict[str, str] | None = None, timeout: float = 10.0) -> APIResponse: """Fetch from a single API with error handling.""" try: response = await client.get( url, headers=headers or {}, timeout=timeout ) response.raise_for_status() return APIResponse( source=name, data=response.json(), error=None, status_code=response.status_code ) except httpx.TimeoutException: return APIResponse( source=name, data=None, error="Request timed out", status_code=None ) except httpx.HTTPStatusError as e: return APIResponse( source=name, data=None, error=f"HTTP {e.response.status_code}", status_code=e.response.status_code ) except Exception as e: return APIResponse( source=name, data=None, error=str(e), status_code=None )
async def aggregate_apis(api_configs: list[dict]) -> list[APIResponse]: """Fetch from multiple APIs concurrently.""" async with httpx.AsyncClient() as client: tasks = [ fetch_api( client, config["name"], config["url"], config.get("headers"), config.get("timeout", 10.0) ) for config in api_configs ] return await asyncio.gather(*tasks)
# Usage exampleasync def get_dashboard_data(user_id: str) -> dict: apis = [ { "name": "user_profile", "url": f"https://api.auth0.com/users/{user_id}", "headers": {"Authorization": f"Bearer {AUTH0_TOKEN}"} }, { "name": "analytics", "url": f"https://api.analytics.com/users/{user_id}/metrics", "headers": {"X-API-Key": ANALYTICS_KEY} }, { "name": "notifications", "url": f"https://api.notify.io/v1/users/{user_id}/unread", "headers": {"Authorization": f"Bearer {NOTIFY_TOKEN}"}, "timeout": 5.0 # Notifications are less critical } ]
results = await aggregate_apis(apis) return {r.source: r.data for r in results if r.data}The key insight here is that asyncio.gather() runs all requests concurrently. If your three APIs have response times of 200ms, 350ms, and 150ms, the total time is approximately 350ms (the slowest), not 700ms (the sum).
💡 Pro Tip: Use
asyncio.gather(*tasks, return_exceptions=True)to prevent one failed task from canceling others. This is essential when you want partial results.
Implementing rate limiting
A robust aggregation service needs rate limiting that works across all your API consumers. Here’s a token bucket implementation that handles multiple API rate limits:
import asyncioimport timefrom dataclasses import dataclass, fieldfrom typing import Callable, Awaitable, TypeVar
T = TypeVar('T')
@dataclassclass TokenBucket: """Token bucket rate limiter for a single API.""" capacity: int refill_rate: float # tokens per second tokens: float = field(init=False) last_refill: float = field(init=False) _lock: asyncio.Lock = field(default_factory=asyncio.Lock, repr=False)
def __post_init__(self): self.tokens = float(self.capacity) self.last_refill = time.monotonic()
async def acquire(self, tokens: int = 1) -> float: """Acquire tokens, waiting if necessary. Returns wait time.""" async with self._lock: await self._refill()
if self.tokens >= tokens: self.tokens -= tokens return 0.0
# Calculate wait time for enough tokens tokens_needed = tokens - self.tokens wait_time = tokens_needed / self.refill_rate
await asyncio.sleep(wait_time) await self._refill() self.tokens -= tokens return wait_time
async def _refill(self): """Refill tokens based on elapsed time.""" now = time.monotonic() elapsed = now - self.last_refill self.tokens = min( self.capacity, self.tokens + elapsed * self.refill_rate ) self.last_refill = now
class MultiAPIRateLimiter: """Manages rate limits across multiple APIs."""
def __init__(self): self.limiters: dict[str, TokenBucket] = {}
def register_api( self, name: str, requests_per_window: int, window_seconds: float ): """Register rate limit for an API.""" refill_rate = requests_per_window / window_seconds self.limiters[name] = TokenBucket( capacity=requests_per_window, refill_rate=refill_rate )
async def execute( self, api_name: str, func: Callable[[], Awaitable[T]] ) -> T: """Execute a function with rate limiting.""" if api_name not in self.limiters: raise ValueError(f"Unknown API: {api_name}")
await self.limiters[api_name].acquire() return await func()
# Global rate limiter instancerate_limiter = MultiAPIRateLimiter()
# Register your APIs at startuprate_limiter.register_api("github", requests_per_window=5000, window_seconds=3600)rate_limiter.register_api("stripe", requests_per_window=100, window_seconds=1)rate_limiter.register_api("openai", requests_per_window=60, window_seconds=60)This implementation ensures you never exceed the rate limits of any provider, automatically queuing requests when limits are approached.
⚠️ Warning: In distributed systems, a single-process rate limiter isn’t sufficient. Use Redis-based rate limiting (covered in the caching section) for production deployments across multiple workers.
Response normalization
Raw API responses are inconsistent by nature. A normalization layer transforms diverse formats into a consistent internal schema:
from datetime import datetimefrom typing import Any, Protocolfrom abc import abstractmethod
class ResponseNormalizer(Protocol): """Protocol for API response normalizers."""
@abstractmethod def normalize(self, raw_response: dict[str, Any]) -> dict[str, Any]: """Transform raw API response to normalized format.""" ...
class GitHubUserNormalizer: """Normalize GitHub user API responses."""
def normalize(self, raw: dict[str, Any]) -> dict[str, Any]: return { "id": str(raw.get("id")), "username": raw.get("login"), "display_name": raw.get("name"), "email": raw.get("email"), "avatar_url": raw.get("avatar_url"), "created_at": self._parse_timestamp(raw.get("created_at")), "source": "github" }
def _parse_timestamp(self, ts: str | None) -> datetime | None: if not ts: return None return datetime.fromisoformat(ts.replace("Z", "+00:00"))
class StripeCustomerNormalizer: """Normalize Stripe customer API responses."""
def normalize(self, raw: dict[str, Any]) -> dict[str, Any]: return { "id": raw.get("id"), "username": raw.get("email", "").split("@")[0], "display_name": raw.get("name"), "email": raw.get("email"), "avatar_url": None, # Stripe doesn't have avatars "created_at": self._parse_timestamp(raw.get("created")), "source": "stripe" }
def _parse_timestamp(self, ts: int | None) -> datetime | None: if not ts: return None return datetime.fromtimestamp(ts)
class Auth0UserNormalizer: """Normalize Auth0 user API responses."""
def normalize(self, raw: dict[str, Any]) -> dict[str, Any]: return { "id": raw.get("user_id"), "username": raw.get("nickname") or raw.get("email", "").split("@")[0], "display_name": raw.get("name"), "email": raw.get("email"), "avatar_url": raw.get("picture"), "created_at": self._parse_timestamp(raw.get("created_at")), "source": "auth0" }
def _parse_timestamp(self, ts: str | None) -> datetime | None: if not ts: return None return datetime.fromisoformat(ts.replace("Z", "+00:00"))
# Registry of normalizersNORMALIZERS: dict[str, ResponseNormalizer] = { "github": GitHubUserNormalizer(), "stripe": StripeCustomerNormalizer(), "auth0": Auth0UserNormalizer(),}
def normalize_response(source: str, raw_data: dict[str, Any]) -> dict[str, Any]: """Normalize a response using the appropriate normalizer.""" normalizer = NORMALIZERS.get(source) if not normalizer: raise ValueError(f"No normalizer for source: {source}") return normalizer.normalize(raw_data)The Protocol-based approach allows easy testing and extension. When you add a new API, you just implement the normalizer interface and register it.
Caching strategies with Redis
API responses often don’t change frequently. Caching reduces latency, decreases API costs, and provides a fallback when external services are unavailable:
import jsonimport hashlibfrom typing import Any, Callable, Awaitable, TypeVarfrom datetime import timedeltaimport redis.asyncio as redis
T = TypeVar('T')
class APICache: """Redis-based cache for API responses."""
def __init__(self, redis_url: str = "redis://localhost:6379"): self.redis = redis.from_url(redis_url, decode_responses=True)
def _cache_key(self, namespace: str, identifier: str) -> str: """Generate a consistent cache key.""" hash_input = f"{namespace}:{identifier}" return f"api_cache:{hashlib.sha256(hash_input.encode()).hexdigest()[:16]}"
async def get(self, namespace: str, identifier: str) -> dict | None: """Retrieve cached response.""" key = self._cache_key(namespace, identifier) data = await self.redis.get(key) if data: return json.loads(data) return None
async def set( self, namespace: str, identifier: str, data: dict, ttl: timedelta = timedelta(minutes=5) ): """Cache a response with TTL.""" key = self._cache_key(namespace, identifier) await self.redis.setex( key, int(ttl.total_seconds()), json.dumps(data) )
async def get_or_fetch( self, namespace: str, identifier: str, fetch_func: Callable[[], Awaitable[dict]], ttl: timedelta = timedelta(minutes=5), stale_ttl: timedelta = timedelta(hours=1) ) -> dict: """Get from cache or fetch, with stale-while-revalidate support.""" key = self._cache_key(namespace, identifier) stale_key = f"{key}:stale"
# Try fresh cache first cached = await self.redis.get(key) if cached: return json.loads(cached)
# Try fetching fresh data try: data = await fetch_func() # Store fresh and stale copies await self.redis.setex(key, int(ttl.total_seconds()), json.dumps(data)) await self.redis.setex(stale_key, int(stale_ttl.total_seconds()), json.dumps(data)) return data except Exception as e: # Fall back to stale data if fetch fails stale = await self.redis.get(stale_key) if stale: return json.loads(stale) raise e
async def invalidate(self, namespace: str, identifier: str): """Invalidate cached data.""" key = self._cache_key(namespace, identifier) await self.redis.delete(key, f"{key}:stale")
# Usage examplecache = APICache()
async def get_user_profile(user_id: str) -> dict: """Get user profile with caching.""" return await cache.get_or_fetch( namespace="user_profile", identifier=user_id, fetch_func=lambda: fetch_user_from_api(user_id), ttl=timedelta(minutes=5), stale_ttl=timedelta(hours=24) )The stale-while-revalidate pattern is particularly powerful for aggregation services. When your cache expires but the external API is down, you can serve stale data rather than failing entirely.
📝 Note: Set different TTLs based on data volatility. User profiles might cache for hours, while stock prices should cache for seconds.
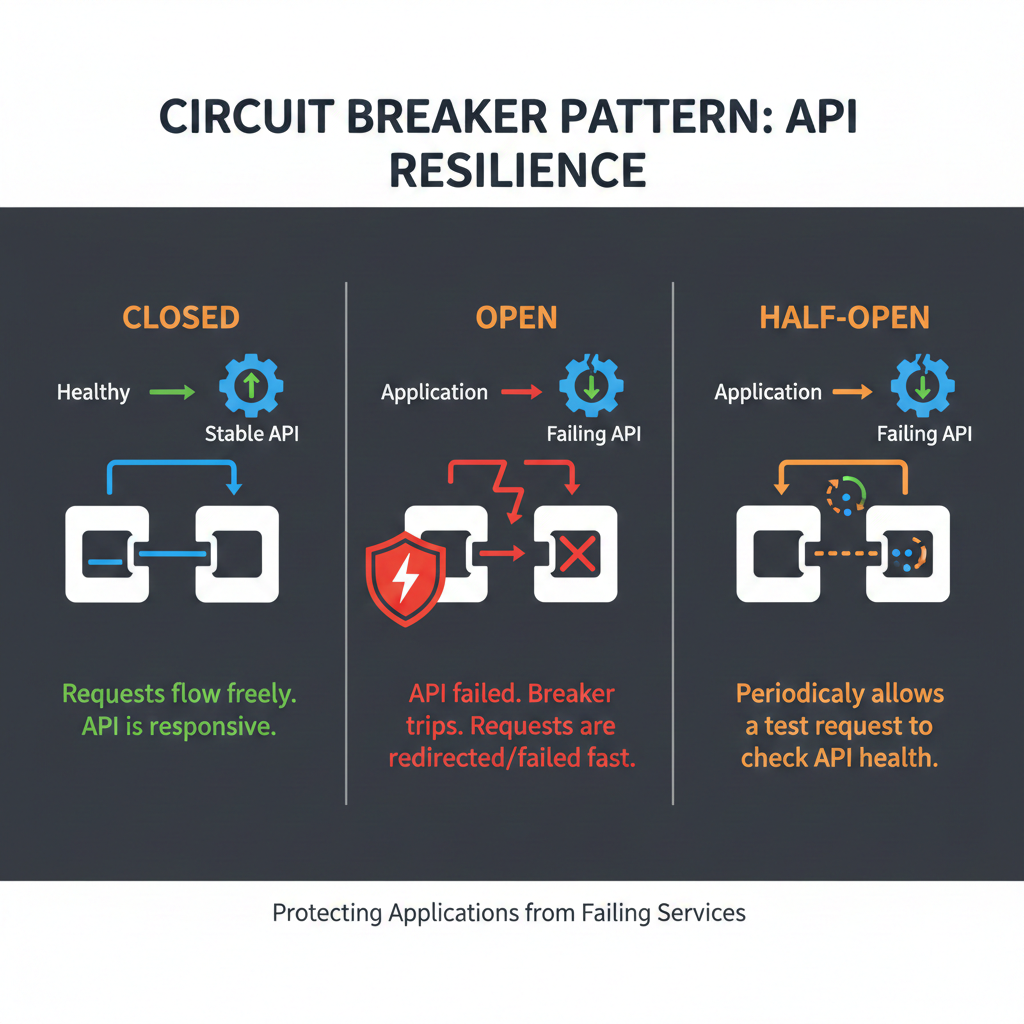
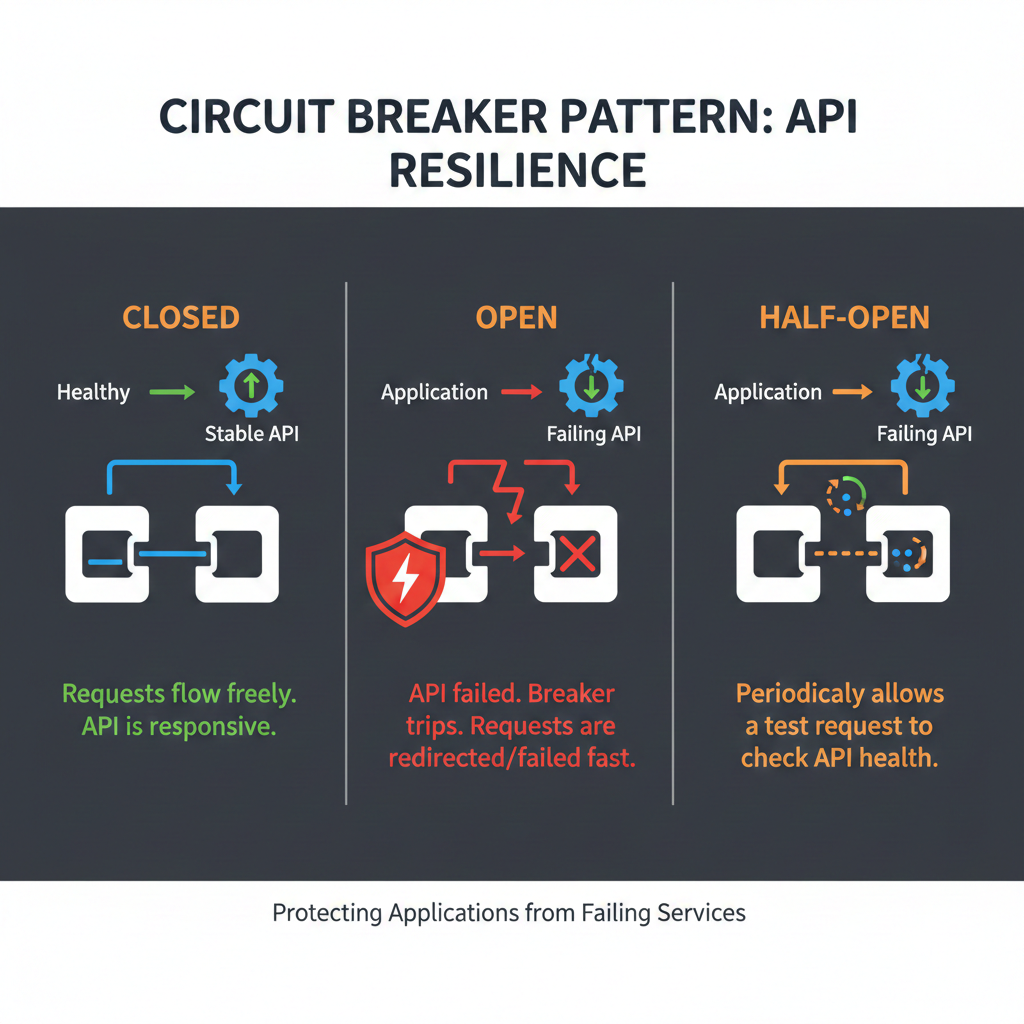
Circuit breaker pattern
When an external API fails repeatedly, continuing to call it wastes resources and slows down your aggregation. The circuit breaker pattern provides automatic protection:
import asyncioimport timefrom enum import Enumfrom dataclasses import dataclass, fieldfrom typing import Callable, Awaitable, TypeVar
T = TypeVar('T')
class CircuitState(Enum): CLOSED = "closed" # Normal operation OPEN = "open" # Failing, reject requests HALF_OPEN = "half_open" # Testing if service recovered
@dataclassclass CircuitBreaker: """Circuit breaker for external API calls.""" name: str failure_threshold: int = 5 recovery_timeout: float = 30.0 # seconds half_open_max_calls: int = 3
state: CircuitState = field(default=CircuitState.CLOSED, init=False) failure_count: int = field(default=0, init=False) success_count: int = field(default=0, init=False) last_failure_time: float = field(default=0.0, init=False) _lock: asyncio.Lock = field(default_factory=asyncio.Lock, repr=False)
async def execute( self, func: Callable[[], Awaitable[T]], fallback: Callable[[], Awaitable[T]] | None = None ) -> T: """Execute function with circuit breaker protection.""" async with self._lock: await self._check_state()
if self.state == CircuitState.OPEN: if fallback: return await fallback() raise CircuitOpenError(f"Circuit {self.name} is open")
try: result = await func() await self._on_success() return result except Exception as e: await self._on_failure() if fallback: return await fallback() raise
async def _check_state(self): """Check if circuit should transition states.""" if self.state == CircuitState.OPEN: elapsed = time.monotonic() - self.last_failure_time if elapsed >= self.recovery_timeout: self.state = CircuitState.HALF_OPEN self.success_count = 0
async def _on_success(self): """Handle successful call.""" async with self._lock: if self.state == CircuitState.HALF_OPEN: self.success_count += 1 if self.success_count >= self.half_open_max_calls: self.state = CircuitState.CLOSED self.failure_count = 0 elif self.state == CircuitState.CLOSED: self.failure_count = 0
async def _on_failure(self): """Handle failed call.""" async with self._lock: self.failure_count += 1 self.last_failure_time = time.monotonic()
if self.state == CircuitState.HALF_OPEN: self.state = CircuitState.OPEN elif self.failure_count >= self.failure_threshold: self.state = CircuitState.OPEN
class CircuitOpenError(Exception): """Raised when circuit is open.""" pass
# Circuit breakers for each external APIcircuits: dict[str, CircuitBreaker] = { "github": CircuitBreaker("github", failure_threshold=5, recovery_timeout=60), "stripe": CircuitBreaker("stripe", failure_threshold=3, recovery_timeout=30), "analytics": CircuitBreaker("analytics", failure_threshold=10, recovery_timeout=120),}
# Usage with fallbackasync def get_analytics_with_circuit(user_id: str) -> dict: """Fetch analytics with circuit breaker and fallback.""" return await circuits["analytics"].execute( func=lambda: fetch_analytics_api(user_id), fallback=lambda: cache.get("analytics", user_id) or {"metrics": []} )The circuit breaker has three states:
- Closed: Normal operation, requests pass through
- Open: After threshold failures, all requests are rejected immediately
- Half-Open: After recovery timeout, limited requests test if service recovered
Monitoring and alerting
An aggregation service without monitoring is a time bomb. Track the health of your external API dependencies:
from dataclasses import dataclass, fieldfrom collections import defaultdictimport structlog
logger = structlog.get_logger()
@dataclassclass APIMetrics: """Metrics for a single API.""" total_requests: int = 0 successful_requests: int = 0 failed_requests: int = 0 total_latency_ms: float = 0.0
@property def success_rate(self) -> float: if self.total_requests == 0: return 1.0 return self.successful_requests / self.total_requests
class AggregationMonitor: """Monitor for API aggregation health."""
def __init__(self, alert_threshold: float = 0.9): self.metrics: dict[str, APIMetrics] = defaultdict(APIMetrics) self.alert_threshold = alert_threshold
def record_request(self, api_name: str, success: bool, latency_ms: float): """Record a request outcome.""" m = self.metrics[api_name] m.total_requests += 1
if success: m.successful_requests += 1 m.total_latency_ms += latency_ms else: m.failed_requests += 1
if m.total_requests >= 10 and m.success_rate < self.alert_threshold: logger.warning("api_degradation", api=api_name, rate=m.success_rate)
def get_health_report(self) -> dict: """Generate health report for all APIs.""" return { name: { "success_rate": f"{m.success_rate:.2%}", "total_requests": m.total_requests, "status": "healthy" if m.success_rate >= self.alert_threshold else "degraded" } for name, m in self.metrics.items() }
# Global monitormonitor = AggregationMonitor(alert_threshold=0.95)Integrate this with your observability stack (Prometheus, Datadog) to track trends and alert on sustained degradation.
Conclusion
Building a robust API aggregation layer requires addressing multiple concerns simultaneously: concurrency for performance, rate limiting for compliance, normalization for consistency, caching for efficiency, circuit breakers for resilience, and monitoring for visibility.
Key takeaways:
- Use async/await with
httpxoraiohttpfor concurrent fetching - sequential calls don’t scale - Implement per-API rate limiting using token bucket or leaky bucket algorithms
- Normalize responses early to isolate format differences from business logic
- Cache aggressively with stale-while-revalidate for resilience during outages
- Deploy circuit breakers to fail fast and protect against cascading failures
- Monitor everything - you can’t fix what you can’t see
The patterns in this article form the foundation of any serious data aggregation service. Start with the basics (async fetching, error handling), then layer on caching and circuit breakers as your reliability requirements grow. The goal isn’t to eliminate failures - external APIs will always fail eventually - but to degrade gracefully and recover automatically.